아스키 코드에서 UTF-8까지
오늘은 아스키 코드에 대해 기본적인 지식만 체크하고 넘어갈게요.
.
.
1. 데이터
컴퓨터가 이해하는 정보를 `데이터`라고 합니다. 그리고 컴퓨터는 0과 1만 이해할 수 있습니다. 이진법을 활용하면 컴퓨터 데이터를 이해할 수 있겠네요.
그렇다면 우리가 사용하는 0과 1 이외의 수많은 숫자와 문자는 어떻게 사용 가능했던 것일까요?
바로 0과 1로 숫자와 문자를 표현할 수 있기 때문입니다.
우리가 텍스트(숫자와 문자 조합)를 입력하면 컴퓨터가 이해할 수 있는 변환하는 과정을 인코딩 이라고 하고,
반대로 컴퓨터만 이해할 수 있는 숫자에서 사람이 이해할 수 있는 문자로 변환하는 과정을 디코딩 이라고 합니다.
2. 아스키 코드
아스키코드는 영문 알파벳을 사용하는 대표적인 문자 인코딩입니다.
- 아스키는 *패리티 비트를 제외한 7비트 인코딩이고총128개로 표현할 수 있습니다.
- 구성 문자는 다음과 같습니다.
1) 33개의 출력 불가능한 제어 문자
2) 공백을 비롯한 95개의 출력 가능한 문자
ㄴ 52개의 영문 알파벳 대소문자
ㄴ 10개의 숫자, 32개의 특수 문자, 그리고 하나의 공백 문자
*실제로는 하나의 아스키 문자를 나타내는데 8비트가 사용됨. 패리티 비트(1비트)는 오류를 검출하기 위한 용도로 사용됩니다.
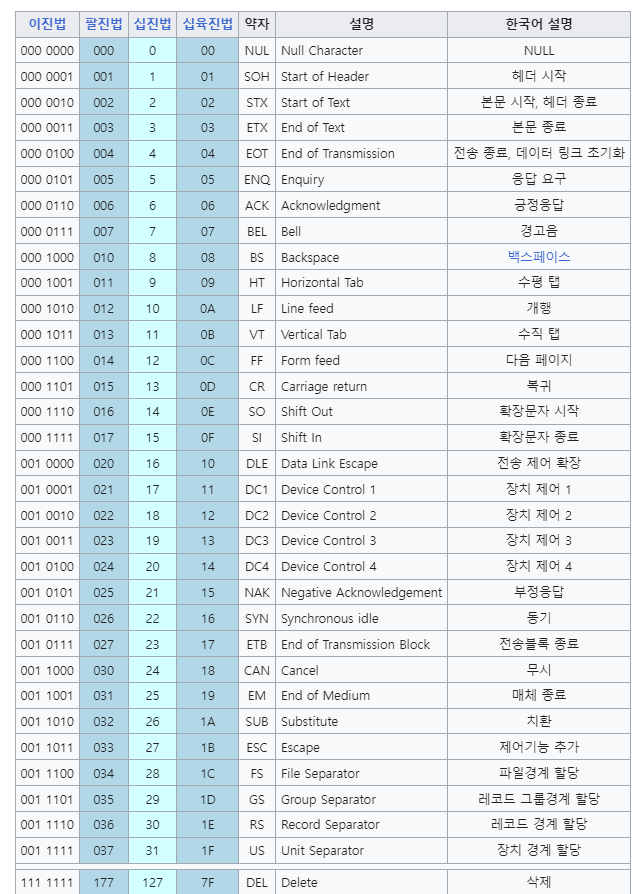


예시를 하나 들면, '65'라는 숫자는 1000001(이진법)으로 인코딩처리가 됩니다.

3. 그렇다면 알파벳을 제외한 한글과 다른 언어들은?
아스키 코드와 같은 문자집합은 알파벳만 등록이 되어있습니다. 그래서 한글과 다른 국가들의 언어의 인코딩을 지원하도록 등장한 개념이 EUC-KR 입니다.
- 8비트 문자 인코딩, EUC의 일종이며 대표적인 한글 완성형 인코딩이기 때문에 보통 완성형이라고 불린다.
ㄴ 완성형 인코딩은 쉽게 말해, '백' 이라는 한 글자에 고유한 코드를 부여하는 방식입니다.
※ 조립형은 ㅂ + ㅐ + ㄱ 과 같이 초성, 중성, 종성에 대한 각각 코드를 부여하는 방식 - 각 글자는 행과 열에 128을 더한 코드값을 사용하여 2바이트로 표현된다.
EUC-KR은 모든 한글을 표현할 수 없는 단점이 있고요. 이걸 보완한게 마이크로소프사에서 도입한 CP949 입니다.
윈도 95부터는 확장 완성형 혹은 통합형 한글 코드(Unified Hangul Code)이라는 명칭으로 확장되어 현대의 모든 한글을 수용하게 되었다고 하네요.
그리고 마침내, 한글 뿐만 아니라 중국어, 일본어 등 각국의 언어의 인코딩을 표준화하여 통일된 방식으로 지원하는 UTF-8로 이어지게 된 것이죠.